GenericProjector rewrite#1938
Conversation
|
Those test failures might just be because one of the optimizations (interpolating rather than projecting non-vertex LAGRANGE DoFs) can also give slightly different results. I guess that's the optimization I'll add back in first. |
|
Now that I've started more extensive testing: The good news: at least with complicated FE types this already seems to be ~25% faster than the previous code, so I'm now much more confident that even the simple cases will be faster after I restore those optimizations. The bad news: this may pass most tests here, but there's still bugs. I haven't found any incorrect results yet, but at least one or two tests I've run hang. |
|
Roy,
We are in the middle of a code release so it’ll likely be next week before I grab the patch and start testing for you. Thanks for the update. I hope this works out.
Adam
On Nov 16, 2018, at 6:46 PM, roystgnr <notifications@github.com<mailto:notifications@github.com>> wrote:
Now that I've started more extensive testing:
The good news: at least with complicated FE types this already seems to be ~25% faster than the previous code, so I'm now much more confident that even the simple cases will be faster after I restore those optimizations.
The bad news: this may pass most tests here, but there's still bugs. I haven't found any incorrect results yet, but at least one or two tests I've run hang.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub<#1938 (comment)>, or mute the thread<https://github.com/notifications/unsubscribe-auth/AqW_pb78tB5Ol6F_S413pm5q7ehB5ZBAks5uv1x1gaJpZM4YgpzQ>.
|
9903231 to
57eddfb
Compare
436d315 to
dd51747
Compare
1c39af5 to
21a66cb
Compare
|
unrelated to this PR, @roystgnr would it help if I modified the civet recipe to not stop at the first failed target? |
|
Nah, in general an early exit is ideal. Sometimes I find that I can't replicate a CI failure and then having subsequent failed cases to try is helpful, but that's very rare. |
|
Well that's interesting. In that initial_adapt test it's not the solution variables that look weird, it's the "box" variable that got set by the BoxMarker. In the gold standard it's 2 in the box and 1 everywhere else; in the broken output it's basically equal to |
|
Okay, I'm actually pretty sure this one wasn't my fault... |
|
No, the 64bit and debug tests still can't find petsc.h. Anyone have any ideas? Oh, and no GRINS tests yet, but that's just the usual "femputer is down again". @pbauman? |
|
I may have finally exhausted the bugs here, so if the plain Test CI passes then I'll do one last pass at interactive rebase cleanup and start throwing parallel sweeps at this thing. |
|
Nope, plain Test CI has the same petsc.h problem |
|
We are actively working with CIVET. We didn't just invalidate because we are trying to understand what was going on. Summary: We've recently added a "clean machine" target to every single event so that the build machines will ensure they have enough space before they run a job. Some of our targets require upwards of 40GBs of space starting from a fresh disk! This will give us a more reliable testing infrastructure moving forward. What this has exposed is obscure problems in our cloning/resetting logic. With nested submodules, it's actually pretty easy to confuse git when you "force delete" a parent submodule, which can cause bad things to happen downstream. |
|
Actually hang on... I see your failure. This has nothing to do with nested submodules... It looks like configure properly detected and configured for PETSc. Oh goodie, another problem to look into. |
|
I am not exactly sure how to fix this. Here is what is happening. As civet launches, it reads a file which instructs it on which 'moose-environment' package to load. The file in question is called 'package_version'. Civet searches for this file in the following order: if
$MOOSE_DIR/package_version
elif
$REPO_DIR/moose/package_version
elif
$REPO_DIR/package_version
else:
use latest available version
fiWhile libMesh does not have a package_version file sitting in the root of its repo, civet will use the latest available version. But later on in the civet recipe, we are doing something else. MOOSE is instructing civet to use a different set of compilers. I need to devise a way, that once a recipe begins, it needs to 'stick' with that set of compilers, regardless what other repos might instruct civet to do. |
Ping me when you come up with a fix or a workaround? I've got no shortage of other stuff I can be working on, but half of it will also hit the "needs MOOSE CI tests to make sure Roy's not being an idiot" stage sooner or later. |
|
A quick fix, is for you to add a file to the root of your repo, instructing civet to use the following package version: echo "repo-hash:56178942a6f4cf47dfc6bb8b678d26bb6c5a32ed" > package_versionThis will allow you to work on this PR today... While we try and solve this for tomorrow. Note: I have a PR into moose which will update it's package_version file... So... unfortunately, once that goes in later tonight, this PR will start failing again... requiring you to update that package_version file to match what moose/package_version contains. Referencing: idaholab/moose#13147 |
|
@roystgnr hold off on adding package_version to your repo (if you were heading that direction)... we are close to figuring out a way to do this without a change on your end. |
|
This was passing the GRINS tests even before those last bugfixes, so I'll take that as gospel even if femputer isn't back up soon. I'm working on unit testing that will improve the libMesh test coverage (I added special code paths to optimize some common MOOSE use cases but then half those weren't properly covered by libMesh test or example cases) and that will in particular cover the original bug report that got me into this mess, and I'll run some sweeps in CI here while I do so, but once that's all done this ought to be finally ready to merge. |
|
Sorry, rebooted femputer, it's running now. |
|
Gah. Both those segfaults are in the --enable-parmesh unit tests, but on my own machines I can sweep those from 1 proc through 24 procs, in debug mode even, with no problems. |
The goals: Make this faster by removing redundant calculations Make this correct even in the corner cases where subdomain-restricted variables are on DoFs owned by processors which don't own that subdomain. The means: Sort projection operations by vertices, edges, faces, interiors, avoiding duplication. Test ghost nodes' patches to see what their owners can compute, and push our computed data to the owners if necessary, in between the steps where it's computed and the steps where it's used. The problems: Looping over vertices/edges/nodes rather than over elements is forcing more context data initialization. This first step is missing some of the common case optimizations that were in the previous version; those need to be re-added.
This fixes a unit test failure for me, hopefully fixes any code further downstream that was relying on our previous interpolation-vs-projection behavior, and ought to avoid us pessimizing those cases.
We can't try to do mixed up MPI communication inside threads the way I was before.
This is useful for getting indices selectively for copying during projections.
This prevents us from having to do a sort or work with an unsorted vector in the new GenericProjector code.
The optimization had been *half* added back, which left bugs as well as pessimizations. This code needs cleanup but it's hopefully correct now.
Counter-intuitively the extra "if" requirement *saves* a branch instruction in some cases and doesn't add one in any case.
This should fail on some partitionings in a similar way to libMesh#1919 did, and so should protect us a little from regressions in the subdomain-restricted-variable support in GenericProjector
This saves a few lines of code and makes it a bit easier to understand
This test breaks (with logic errors) before the GenericProjector refactor
This makes it easier to play with the --re option when debugging tests, and any options that work well for our example codes are surely going to work well enough for our unit tests too.
b3955ed to
fab2cf0
Compare
|
I'd love to get more eyes on this first (@jwpeterson, @bboutkov, @ajamar1 ?), but at this point I think it's ready to merge assuming CI is still happy with the last swath of new cppunit assertions. Most of the recent failures in the new test coverage turned out to be bugs in master too, and at least in my own runs this PR is now passing all the new testing with flying colors (which is more than I can say for master, even after the first rounds of fixes, because the third fix would be harder to backport). |
This makes testing easier and might help other use cases too.
If we have subdomain-restricted variables, and we ask to evaluate one on a boundary between elements that support the variable and elements that do not, obviously we never want to try evaluating on one of the latter.
|
Ok, now I've got test coverage that seems to fail reliably on master in the same way as #1919 did and that works reliably on this PR for me, so hopefully we can avoid any future regressions in the bug that started this whole mess! If CI is still happy too then I'll merge. |
|
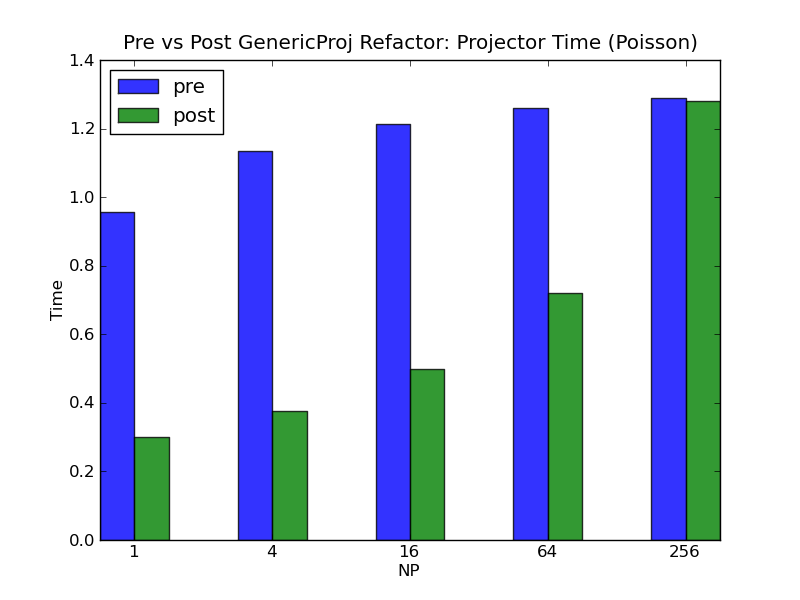
So I gave these changes (without the last 5 commits) a whirl yesterday, and the overall results are looking good. First of all, in terms of correctness, I was not able to produce any failures after testing various configurations targeting GMG + extensive use of I also took a look at overall weak scaling timings for GMG on Poisson and how I was affected by this PR. For overall timing, these changes shave off ~0.5s off each run up to np256, so that seems to be in line with the cleanup. Since I didn't see too much overall change I also looked at the timing of the GenericProjector itself and noticed a bit of a curiosity (see plot below). While the speedup was fairly consistent up to np64, afterwards it wasn't as noticeable. I wasn't quite able to track down any particular reason for this, partly because these timings are subject to about as much variability from run to run as the difference between the pre vs post changes, but after a few tries I was able to consistently replicate this difference at np256. Perhaps its OK, since after all these timings are less than a couple of seconds for 55k local elem for the big run, but I figured I would make the note since I wasn't able to get any higher proc count runs in time to ensure this issue doesn't get even worse at higher proc counts.
|
|
Thanks for that! The last five commits are all new tests, new features for use in new tests, or fixes for new tests, so shouldn't affect any of your results. What's nasty here is that I'm afraid we expect some loss of scalability, because the fix for #1919 necessarily entailed communication steps that didn't exist in the original algorithm; better to get the right answer slowly than to get the wrong answer quickly. I was hoping for the crossover point to be in the tens of thousands of processors, though, not in the hundreds. We might be able to mitigate the problem slightly (and improve some other areas) by enabling more overlap of communication and calculation. #1965 was actually a tiny regression in that respect (though utterly worth it for the asymptotic speedup in the common case), so we should have some room to improve, and I've been thinking about how. Oh, and wait a minute - those timings of yours are for the GMG projection matrix constructions, right? I'm afraid one of the sends for that case doesn't use the new algorithm from #1965, because that currently is only available when sending vectors of fixed-length types, whereas the projection matrix rows have to get sent as vectors-of-vectors, which falls back on my intermediate alltoall-limited algorithm, which means we expect a serious loss of scalability. So the good news from most users' perspective is that you're kind of the worst-case scenario here, but the bad news from your perspective is you're kind of the worst-case scenario here! I apologize! If you have any plans to do GMG on thousands of cores in the near future, let me know, and I'll bump that optimization up higher on my todo list. |
I'm posting this at an early stage, both so it can get into CI (it's passing my local tests now but this is a huge change that could have all kinds of corner cases) and so @ajamar1 can try it out (it passes the test case in #1919 for me, at least), but anybody who isn't running the impacted transient-repartitioning-of-subdomain-restricted-variables case isn't going to want to use the current unbenchmarked bag of optimizations mixed with pessimizations in the first commits here. This is going to need more optimization work before it's ready to merge.
The goals:
Make projections faster by removing redundant calculations
Make projections correct even in the corner cases where subdomain-restricted
variables are on DoFs owned by processors which don't own that
subdomain.
The means:
Sort projection operations by vertices, edges, faces, interiors,
avoiding duplication.
Test ghost nodes' patches to see what their owners can compute, and
push our computed data to the owners if necessary, in between the
steps where it's computed and the steps where it's used.
The current problems:
Looping over vertices/edges/nodes rather than over elements is forcing
more context data initialization.
This initial commit is missing some of the common case optimizations that
were in the previous version; those need to be re-added.