Dated Notes
Moved to this issue.
For all of this think of several concrete use cases:
- I have two dropdown elements called A and B: A's options are the keys of a mall, and B's options are the keys of the store selected in A.
- My GUI experience to select something from a store is as follows: I see a table with information about all the keys of the store, and if I select a row of the store, I see a preview of the value behind it.
- I specify my sample rate once (in a specific form that deals with defaults, or simply in any form asking me for a sample rate) and all future forms use that same sample rate as their default (over-writable or not) value
embody is meant to be a package that offers a generalization of formatted strings. That is, being able to make a templated objects of any type (not just strings). Consider the possibilities when used recursively.
embody, or at least the problem pattern it's meaning to cover, is related to front in that some elements (as well as their parents and children) can be not-fully-specified, but become so by injecting information on the context.
One old (2020!) issue, called Stateful operations, has basically resulted in crude.py. I closed that issue now, with a few comments.
Notes on input and output translation is another related old wiki (also 2020, but updated Jan 2021) to check-out in this context.
The use of state to communicate (data bind?) between elements (whether with crude, or other state mechanisms) can lead the user to create buggy apps. Some scope management is needed. On this subject, see:
Let's write a use case with a minimal store_here = do_this(with_this, and_this,...) language:
from meshed.makers import code_to_dag
@code_to_dag
def use_case():
stream = get_wf(data_src, user, pwd)
chunks = chunker(stream)
model = learn_model(learner, chunks)
results = apply_model(model, stream)use_case is now a working object that can be viewed and run, therefore tested.
The default functions (usually representing user actions or use case steps)
are just placeholders, but one can then "inject" the actual functions that should be used.
This means that we can test the use case with backend functions, webservice functions,
and/or GUI functions.
use_case.dot_digraph()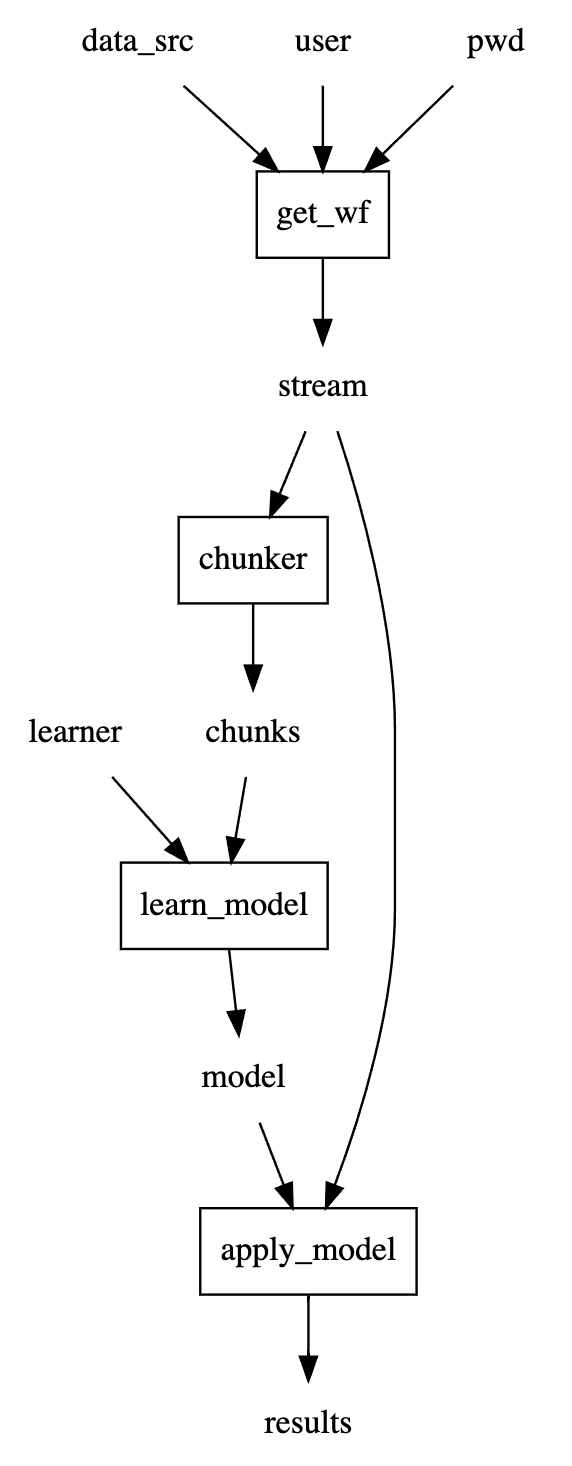
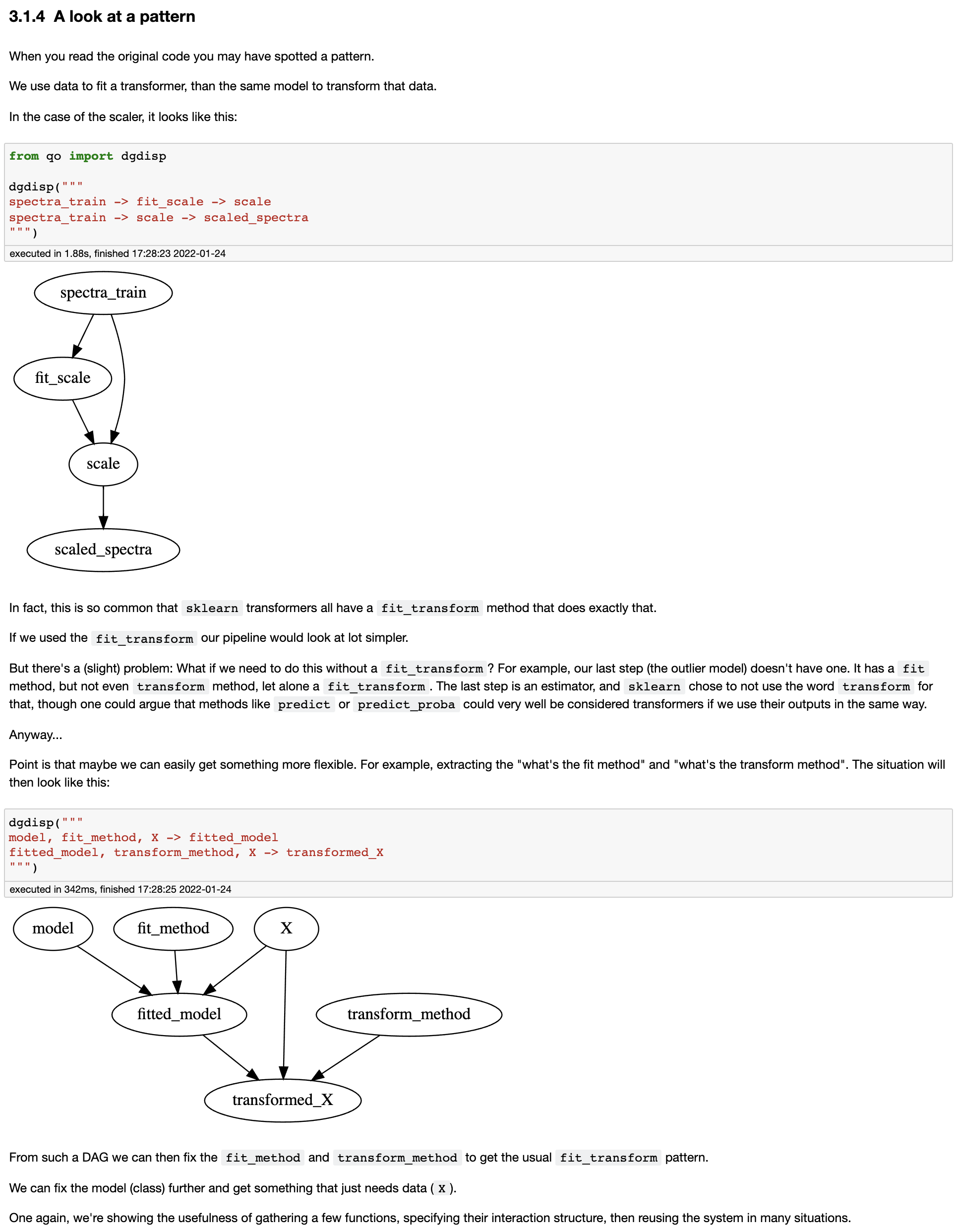
One more time, the design pattern I'm proposing is that when you need to dispatch a function like
train(learner, data)where learner and data are complex python objects, you do it by creating three components:
- CRUD for learners
- CRUD for data
- train component, which points to the learner and data CRUD components to get its inputs
The CRUD components are made of two parts
- For the creation of the object: A specific UI component
- For all other CRUD operations: A (py2)store that can handle the type of objects being made
Sometimes the creation will itself require some complex object inputs. For example, the case of model in:
run(model, data)
But a model is just the output of train(learner, data), so we fall back on the train component,
which in turn relies on the learner and data components.
In general, a stateful server is one where the server maintains either global or user-specific session data (as opposed to persistent data in as a database). It is considered a general best practice in software architecture to keep servers stateless when possible, to reduce the complexity when scaling up.
In the case of a single client with a single server (as in a dedicated demonstration platform or a developer working locally), it can be acceptable to maintain global state on the server, because the entire application is defined as having one continuous session with one user at a time.
In the case of a single server with multiple clients, it is possible to store user sessions in memory. Then the server just needs a way to identify the user for each request and read and write from the user's session when necessary. The user session data may be in a format that is not easy to serialize.
In the case of a distributed server (over multiple processes) with multiple clients, it is necessary to add a separate storage layer for user sessions, such as a Redis cache. This also means that user session data must be serialized and deserialized when it is accessed.
Data scientists natural workflow happens in a notebook.
Data is pulled and transformed, models learned, results visualized, and in the middle of all that,
instances created and values assigned to variables.
The state aspect exists, but is invisible: It's taken care of by locals() -- the dict that takes care of storing variable values --
as well as the In and Out dicts that store input and output cell code.
Side note 1: state is actually not completely invisible, just not "apparent" most of the time; but state does come and bite notebook-dwellers in the behind quite regularly, creating all kinds of WTF havoc. Still, the benefits of notebook development are worth that cost.
Side note 2: We can do a lot more with locals, In, and Out to help reduce the boilerplate in notebook-to-rest-of-the-world efforts
(to gui, but also to clean python modules, tests, documentation...)
For the backend and frontend engineers, state is not an invisible problem (I blame the immaturity of tech). So how do we bridge the gap? The notebook-dwellers can be taught some better habits, but the state concern shouldn't infect theirs (that would be a violation of SoC), so that's only a partial solution.
What we'd like are tools to semi-automatically reshape/layer the analysts' user story into the backend/frontend context.
Ideas:
- Allow multiple steps to be bundled into one stateless unit. Relevant; graphQL, meshed, ...
- Enable client side caching
- Enable sessions in http services
- Have more powerful state managers in GUI code (relevant; scoped access)
With py2http2py we have:
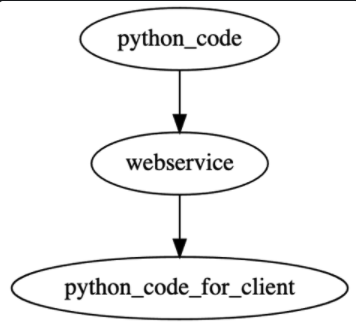
Having tools that allow one to easily add caching
(using builtin functools.cached_properties and functools.lru_cache, or third party like cachetools) can help to
create "session controllers" that have less "re-computation waste".
Further, py2http2py could be made to dispatch only SOME of its objects transformed to webservice clients (wrapped in a python interface), and others could be left as the original python. If we do this we'd to have tools that help us analyze/manage/validate dependencies.
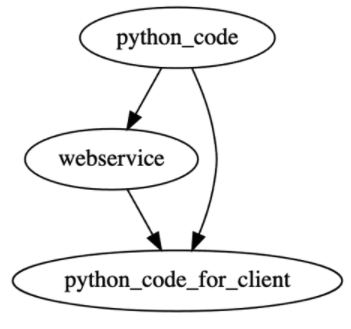
We're solving the "python to GUI" problem by explicitly (e.g. py -> ws -> wspy -> streamlit) or implicitly (e.g. py -> streamlit)
dispatching python functions to an http service that will be used in the GUI, but there are other options to port python
functionalities to the GUI context. There are "interpreter" solutions to allow subsets of python to run in the browser or
"translator" solution that will produce standard JS code from python.
See for example, this article,
but there is more (find awesome lists for example).
An analyst/data_scientists makes a notebook that solves a client's user story. It works on her machine, but now has to share it with someone else. That someone else could be:
- Charlie, a client-facing engineer (employee of same company) that doesn't know too much python, has some basic python tools on his computer, but doesn't maintain the necessary python tools for all that the analyst uses.
- Oscar, a non-engineer employee who is client facing.
- Zulu, a client. She might be anonymous, or might be collaborating with her. But unlike Charlie and Oscar, she is not an employee, so need to be careful of the code we share, how ugly and buggy what we share is, what tracebacks are shown when there's exceptions, etc. Also, authentication might be necessary.
So:
- Charlie can use a notebook, but would be better if it came with a docker container and/or webservice to avoid many installation differentials.
- Oscar needs to use a GUI (with docker or web-service behind). He would use the new GUI before any client sees it.
- Zulu should use a GUI (backed by docker, local web-service, or remote web-service depending on the case)
See notebook here --> search for "audio outliers".
A few highlights of the notebook

Major refactor of front. Moved most of it's contents to streamlitfront and opyratorfront, adapting readmes, setup.cfg and "tests" accordingly.
All three CIs pass.
Note that the tests are cursory. Only unit tests or placeholders to verify dependencies. TODO: Think of different ways to test (quicker but deeper for now, and what a more significant test tool might look like in the future -- see the section on "User Story Test Driven Development" below)
Some utils to seed the py_to_pydantic effort: https://github.com/i2mint/front/blob/cd2c073ed5308c483619d722077f32e0d1404b43/front/scrap/py2pydantic.py#L2
To do this:
>>> from i2.tests.objects_for_testing import formula1
>>> test_func_to_pyd_model_of_inputs(formula1)
>>> pyd_model = func_to_pyd_model_of_inputs(formula1)
>>> pyd_model
<class 'pydantic.main.formula1'>
>>> from i2 import Sig
>>> Sig(formula1)
<Sig (w, /, x: float, y=1, *, z: int = 1)>
>>> Sig(pyd_model)
<Sig (*, w: Any, x: float, z: int = 1, y: int = 1) -> None>Consider the two user stories:
- As a user, I can make an audio classification model trained on tagged audio data (and get confirmation that it's been done)
- As a user, I can run an audio classification model on some input audio
Here's some vacuously working code:
DFLT_MODEL = lambda *args, **kwargs: "catch_all_tag" # this model systematically returns a catch all tag
DFLT_TRAINER = lambda *args, **kwargs: DFLT_MODEL # this model
DFLT_WITH_MODEL_ACTION = lambda *args, **kwargs: print("Done")
def train_audio_classification_model(
audio, annotations, trainer=DFLT_TRAINER, with_model_action=DFLT_WITH_MODEL_ACTION,
):
audio = select_audio(...)
annotation = select_annotations(...)
model = trainer(audio, annotations)
return with_model_action(model)
def run_model(audio, model):
model = get_model(model)
return model(audio)From there, we want to be able to make and test alternative "fronts" (dispatches, interfaces, apps) for the user actions needed in in the user story, and test user story with these alternative fronts.
Let's on the train_audio_classification_model user story.
user_story_func = train_audio_classification_modelThe "action functions" 'train_audio_classification_model' uses, could be explicitly imported and specified:
action_funcs = [select_audio, select_annotations, trainer, with_model_action] But if user story functions are required to be simple enough (e.g. only function calls, or function calls an assignments of returned values) these could be extracted from the user_story_func itself (through AST) Alternatively, we could user story in with some custom object that makes the requred action functions easier to extract.
import pytest
core_tester = pytest.mark.parametrize(...)
core_test = core_tester(user_story_func)ws = dispatch(action_funcs, kind='webservice')The ws object here could have stuff like ws.action_funcs_openapi_specs, ws.run(), etc.
deployed_ws = publish(ws, ...)This deployed_ws could be the same as (or contain) ws, but
with extra info about the deployment/publication
ws_action_funcs = dispatch(
deployed_ws, kind='webservice_binders'
)Make a user_story_func version that uses the webservice through the language binders
That is, it uses the same code (text) as user_story_func, but sources it's action functions
from ws_action_funcs (monkey-patching?)
Test it (with the same user story test, but using the ws_action_funcs function)
ws_user_story_func = monkey_patch(user_story_func, ws_action_funcs)
ws_test = core_tester(ws_user_story_func)ui = dispatch(action_funcs, kind='ui')ui_action_funcs = dispatch(ui, kind='webservice_binders')ui_user_story_func = monkey_patch(user_story_func, ui_action_funcs)
ui_test = core_tester(ui_user_story_func)Select a few existing apps that we have business-logic python code for, and buildup the tools to recreate their functionality semi-automatically, from the core python code.
Further notes/tasks:
- Note I said "functionality". This does not mean
frontneeds to reproduce the same UI elements, layout, etc; it just needs to allow a user to complete the same user story through UI elements - Ideally: Write user story tests for the (functionality of the) selected apps
- Select a priority/central app to start with, keeping in mind that the tools should work for the others too
- Time-box all efforts and take note of the difficulties/complexities, their reasons, possible solutions...
- Simplify the apps just enough to make the sprint feasible
As always, central to our effort here is wrapped_obj = wrap_this(obj, wrapping_specs).
For example, opyrator wants us to express what we need as a function taking a single annotated
pydantic.BaseModel input with an annotated return value also of the pydantic.BaseModel type.
(Contrast this with a flask webservice that needs to take a Request object and return a Response object.)
Our point of departure is a set of python objects (say, sorta without loss of generality), some functions, that should (because it's a good principle) have been written without web-services, CLIs, or UIs in mind.
How do we get to what opyrator wants? By writing separate code to get us there.
How do we minimize boilerplate in doing so, and do so in a consistent and uniform manner? By trying to extract as many declarative aspects as possible.
For the opyrator target, I propose we use
i2.wrapper
to make source functions into a opyrator compatible function.
This will require setting up input/output translation logic. See i2.io_trans, i2.routing_forest and i2.switch_case_tree for tools that can help doing this.
We should familiarize ourselves with pydantic since it is an extremely popular package currently
(though I do have reservations, mentioned below -- perhaps we can "datafy" that aspect too,
meaning express the parameters of the pydantic objects in builtin python, and construct pydantic objects
from there (allowing us to switch to a different container if we wish)).
I've made some light pydantic like efforts in the past, in an effort to solve problems such as
- centralization of types, their names, their description
- add extra constraints to builtin types
- data validation (seeded here viable)
- data generation (for testing) (see forged and hum)
To mention a few: i2.itypes, and (intended to be a ledger for types used in audio recognition) atypes.
There are some tools out there to infer types. Some of these do so by running code monitoring what functions are called and with what argument (types). This means that we can get help annotating functions in-so-far as we have test coverage! Quite a positive alignment, since it motivates us further to cover code with tests.
There's some code in i2.footprints that does some of this "dynamic monitoring" of code, but (1) the initial motivation of footprints was different (2) it's only at the POC level, and (3) there's third party code out there that might be more fitted for our purpose.
opyrator uses fastapi for its http service needs. Read this comparison of flask vs fastapi.
fastapi uses pydantic. That it (as far as I can tell) it relies on functions being pydantically annotated to be able to then extract the information it needs to map python elements (input and return objects' names and values) to web service elements (including openAPI spec). It seems like opyrator assumes pydanticism too, to be able to get it's descriptions, numerical ranges (even the "step" of sliders), etc.
In short, I'd say we should put a bit of time getting familiar (by USING) the pydantic/fastapi/opyrator trinity,
but time-boxed and keeping the goal (what and why) in mind.
I've been hearing about pydantic and fastapi for awhile, and it seems (1) extremely popular and (2) very much have an i2i flavor to it.
In fact, I've been poking around it and it's "alternatives" (see below) for awhile, looking for solutions/inspirations for SoC solutions for typing, validation, transformation (includes serialization, RPC, ...),
centralized-documentation, and any boilerplate reducing and correctness/completeness increasing means.
At this point, my critique of the trio under analysis here is that:
- they're heavy
- they're boilerplaty in that they require everything to be annotated with specify types
BUT... If we consider the annotation requirement as being the "long/explicit language", and develop the tools to allow these rich annotations to be separated (and reused!), then I'm more than okay with it. At least it allows us to not reinvent that long language, and the heaviness only affects the webservice/ui concerns -- not the core python code itself.
- Builtins:
dataclasses,typing(namelytyping.Protocol) - attrs (comparison]
- marshmallow
- mypy
- flask (comparison)
- bottle
- aiohttp
Here are some good examples for opyrator usage.
The "playground" and "demos" didn't work for me, but the "Run this demo on your machine (click to expand...)" instructions did work for me (I tried the "Question Answering" one).
Get from functions to browser based UI semi-automatically, where:
- Service (web or js) is a separate concern — minimum: a front-ender can just use the web-service part of the app
- Service has a spec (like OpenAPI spec), so that language-binders can easily be made Input/Output trans (io casting?) is separate and has boilerplate-reducing tooling (e.g. arg-name and type mapping), so that backend functions can be "pure" (no trace of the web-service or UI concerns)
Proposal: Use https://github.com/i2mint/front as to aggregate code, discussions, tools, as well as issues and wikis. front is now tied closely to streamlit, but the goal is that the ui be made as a replaceable layer/plugin just as flask, bottle and aiohttp are plugins for py2http.
Our stuff on getting web-services from python functions:
- The new way: https://github.com/i2mint/py2http (see Steve and Valentin)
- A small "quick" layer on it: https://github.com/otosense/qh
- Older version: https://github.com/thorwhalen/py2api
Our stuff on getting UIs from python function
- python to streamlit UI app: https://github.com/i2mint/front
- DAG to app using streamlit: https://github.com/i2mint/dagapp
- python to dash UI app: https://github.com/i2mint/py2dash
Tool to (apparently) go from python functions (that are pydantic-typed) to UI, but with separable layers (web-service and web-service-specification (like OpenAPI?)): https://github.com/ml-tooling/opyrator